物件導向程式設計的原則之一, 是讓實作和界面分開, 以便讓同一界面但不同的實作的物件能以一致的面貌讓外界存取, 為了達到此目標, java允許設計人員規範類別成員以及類別本身的存取限制。
所謂封裝(Encapsulation),是指class A的設計者可以指定其他的class能否存取A的某個member。Java定義了四種存取範圍:
public class EncapsulationExample {
private int privateVariable;
int packageVariable;
protected int protectedVariable;
public int publicVariable;
private int privateObjectMethod() {}
int packageObjectMethod() {}
protected int protectedObjectMethod();
public int publicObjectMethod();
static private int privateClassMethod() {}
static int packageClassMethod() {}
static protected int protectedClassMethod();
static public int publicClassMethod();
}
如果member的前面沒有private,protected,public其中一個修飾字,則該member的存取範圍就是package。從以上的敘述,讀者可以推知這四種存取範圍的大小是public > protected > package > private。
所謂package,可以想成是在設計或實作上相關的一群class。要宣告某class屬於某package,其語法為
package myPackage;
public class MyClass {
}
如果沒有宣告package的話,如下面這兩個class,就會被歸類為「匿名」的package:
// in file ClassA.java
public class ClassA {
public static void main(String[] argv) {
ClassB x = new ClassB();
}
}
// in file ClassB.java
public class ClassB {
}
為了讓JVM在執行期間能夠找到所需要的class,同一個package的class會放在同一個目錄下。不過只知道目錄的名稱還不夠,還需要指定該目錄在檔案系統內的路徑。classpath這個環境變數是由多個以分號隔開的路徑所組成,JVM透過classpath配合package的名稱就可以找到所需要的class。如果我們只用到Java標準的程式庫,則不需要指定classpath。指定classpath環境變數時,要特別注意的是,不要忘了把.(代表目前的工作目錄)放到最前面,否則就找不到「匿名」package裡的class(別忘了絕大部分簡單的範例都沒有宣告package,所以都是匿名的)。
classpath=.;n:\計網中心系統組\project;
classpath裡除了路徑外,也可以指定zip或jar(java archive format)格式的檔案。zip和jar可以把目錄及其子目錄內的檔案都壓縮起來,因此可以透過這類檔案抓到所需的class檔。
classpath=.;c:\mylib.zip;c:\otherlib.jar;n:\計網中心系統組\project;
package的宣告可以用.號構成複雜的package tree。
package mylib.package1
public class A {}
package mylib.package2
public class B {}
屬於mylib.package1的class會放在mylib目錄下的package1目錄內。Java所提供的標準應用程式介面(Application Programming Interface, API)就是一個複雜的package tree。
同一個.java檔裡面, 可以定義好幾個class, 但最多只能有一個宣告為public class。此限制是因為java希望每一個編譯的單元(.java檔)都有唯一的界面宣告。那麼public class和class的區別何在? non public class只能給同一個package內的其他class引用, public class則可以給任何class引用。
假如Class A用到package myPackage裡的Class B, 為了檢查A使用到B的部分是否符合B的原始定義, 諸如方法存不存在, 參數正不正確等問題, Compiler必須引入class B的定義, 以便進行編譯時期的檢查。引入的語法為
import myPackage.B;
這裡要強調的是, import指令告知Compiler在Compiler time所要檢查的類別定義在哪裡。但有時候我們編譯的環境和執行的環境可能不同, 例如編譯時用JDK 1.4, 執行時卻用JDK 1.2, 若程式使用到JDK 1.4才有的API, 那麼會在執行期間產生錯誤。
有時候我們會引用相當多個同屬某package的類別, 如果要一個一個import, 會很煩人, 因此Java允許我們使用萬用字元*來代表某package裡的所有class:
import myPackage.*;
public class A {
public static void main(String[] argv) {
B x = new B();
}
}
眼尖的讀者會發現我們並沒有import String的定義啊, 怎麼都沒有問題? 由於寫程式多多少少都會用到一點系統提供的程式庫, 如果連很簡單的程式都要import一堆class, 也真煩人。因此Java Compiler會自動幫我們引入java.lang.*
public class Hello {
public static void main(String[] argv) {
System.out.println("Hello World.");
}
}
就等同
import java.lang.*;
public class Hello {
public static void main(String[] argv) {
System.out.println("Hello World.");
}
}
由於class是放在類似樹狀結構的package tree裡面, 因此引用的class應該加上完整的package路徑才是全名, 例如
public class Hello {
public static void main(java.lang.String[] argv) {
java.lang.System.out.println("Hello World.");
}
}
只要不會造成混淆, 一般我們都使用省略package路徑的class簡稱。但是如果我們import P1和P2兩個package, 而這兩個package碰巧都定義了同名的class A, 則用到A的地方就比需以P1.A和P2.A來區別了。
package p1;
public class Access {
private static void f1() {}
static void f2() {}
protected static void f3() {}
public static void f4() {
Access.f1();
}
}
package p1;
public class Example1 {
public static void main(String[] argv) {
Access.f1();
Access.f2();
Access.f3();
Access.f4();
}
}
package p2;
import p1.*;
public class Example2 {
public static void main(String[] argv) {
Access.f1();
Access.f2();
Access.f3();
Access.f4();
}
}
package p1;
public class Example3 extends Access {
public static void main(String[] argv) {
Access.f1();
Access.f2();
Access.f3();
Access.f4();
}
}
package p2;
import p1.*;
public class Example4 extends Access {
public static void main(String[] argv) {
Access.f1();
Access.f2();
Access.f3();
Access.f4();
}
}
傳統程式開發的流程是Compile個別Source Code,然後Link所有的Object Code成為執行檔。對大型的應用程式來說,常見的問題之一是如何確定Link時所需的Object Code是由最新的Source編譯而來?尤其模組間存在相依性,如模組A可能用到模組B裡的函數,如果B的函數有修改參數,則A模組也要重新編譯。換句話說單看source code和object code的產生時間是不行的。最簡單的方法就是在Link前將所有的Source Code重新編譯一次,但這樣做有以下幾個問題:
由於這些問題的存在,某些原始碼管理系統便因應而生,例如UNIX上的SCCS(Source Code Control System)。Java Compiler具有下面兩個功能,可以在沒有原始碼管理系統的情況下,也能解決上述問題:
如果應用軟體只有單一的進入點,例如class A的public static void main(String[] argv),則只要編譯A.java就會自動編譯其他需要重新編譯的.java檔。如果應用軟體有兩個以上的進入點,如網路程式的client端和server端的進入點會不一樣,只要寫個批次檔編譯相關進入點的.java檔即可。
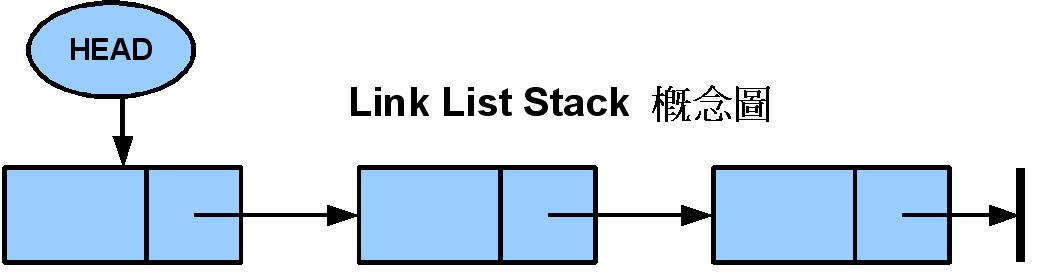
class Node {
Object data;
Node next;
}
public class Stack {
private Node head;
private int size;
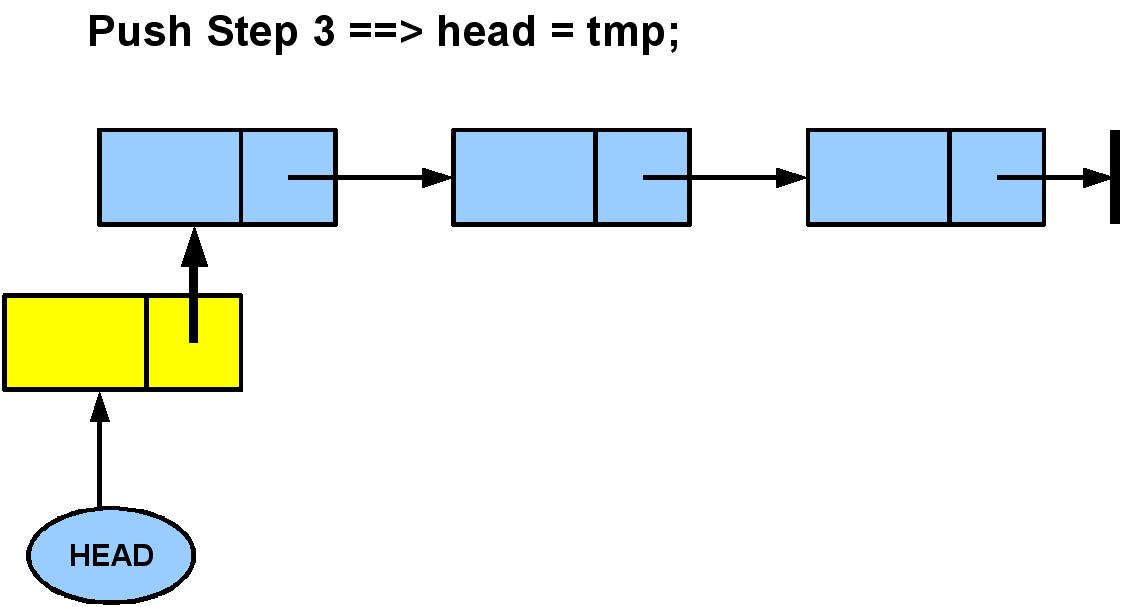
public void push(Object s) {
Node tmp = new Node();
tmp.next = head;
tmp.data = s;
size++;
head = tmp;
}
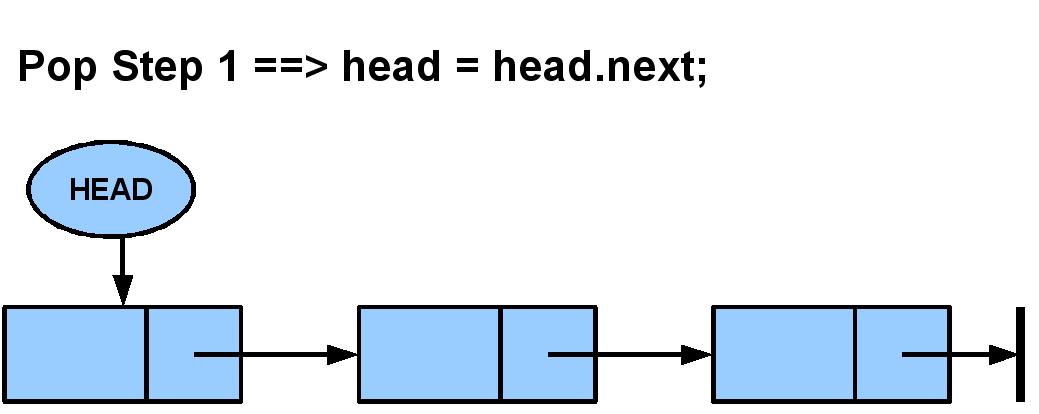
public Object pop() {
Object tmp = head.data;
head = head.next;
size--;
return tmp;
}
}


public class Example {
public static void main(String[] argv) {
Stack s1 = new Stack();
Stack s2 = new Stack();
s1.push("abc");
s1.push("def");
s2.push("123");
s2.push("456");
}
}
class Node {
Object data;
Node next;
}
public class Queue {
private Node head, tail;
private int size;
public void put(Object s) {
Node tmp = new Node();
tmp.data = s;
if (tail != null) {
tail.next = tmp;
} else {
head = tmp;
}
tail = tmp;
size++;
}
public Object get() {
Object tmp = head.data;
head = head.next;
if (head == null) {
tail = null;
}
size--;
return tmp;
}
}